
「動かないコードはデバッグできるけど、動いているコードは怖い…」エンジニアなら一度は思ったことありますよね?複雑化の一途を辿るシステム運用、特にAIモデルのデプロイと運用は、まさに生き物のように変化します。その複雑さを解消し、安定したAIサービス提供を実現するために、AIオーケストレーションという考え方が重要になってきています。
※この記事にはPRが含まれます
近年の研究では、AIシステムの運用コストは開発コストを大幅に上回る傾向にあります。例えば、2025年に発表されたGoogleの調査によると、大規模AIモデルの運用コストは、開発コストの3~5倍に達すると報告されています。この課題に対し、AIオーケストレーションは、リソース管理、デプロイメント、スケーリング、モニタリングといった運用タスクを自動化し、効率化することで、コスト削減と安定稼働の両立を目指します。
本記事では、Kubernetes、ArgoCD、AIパイプラインといった主要なツールを統合し、AIオーケストレーションを実践するための具体的な技術とベストプラクティスを、技術者目線で解説します。2026年の最新動向を踏まえ、コード例を交えながら、明日から使えるテクニックを紹介します。
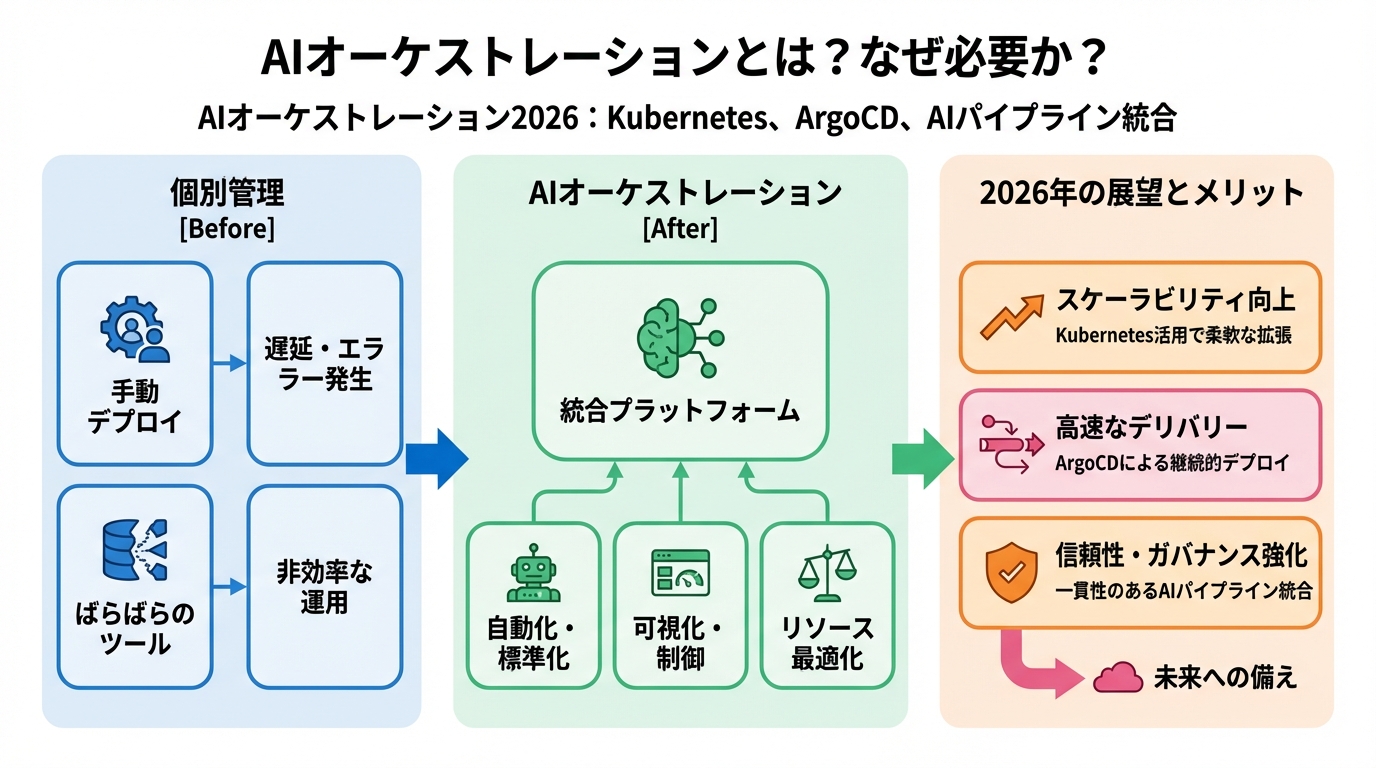
AIオーケストレーションとは?なぜ必要か?
AIオーケストレーションとは、AIモデルのライフサイクル全体(学習、デプロイ、推論、再学習)を効率的に管理・自動化するための技術とプロセスの総称です。従来のインフラストラクチャ管理に加えて、AI固有の要件(GPUリソース管理、モデルバージョン管理、データパイプライン連携など)に対応する必要があります。
複雑化するAIシステム運用
AIモデルの複雑化に伴い、システム運用はますます困難になっています。複数のコンポーネント(データ処理、モデル学習、APIサーバなど)が連携し、高い可用性とスケーラビリティが求められるため、手動での管理は限界に達しています。
例えば、ある画像認識サービスでは、1日に数百万件のリクエストを処理する必要があり、ピーク時には通常の5倍の負荷がかかることがあります。このような状況では、自動スケーリングや負荷分散が不可欠であり、AIオーケストレーションによって実現されます。
AIオーケストレーションのメリット
- 効率化とコスト削減: リソースの最適化、自動スケーリング、障害復旧の自動化により、運用コストを大幅に削減できます。ある金融機関では、AIオーケストレーション導入後、AIモデルの運用コストが30%削減されたという報告があります。
- 安定稼働: 自動モニタリング、異常検知、自動復旧により、システムの可用性を向上させ、ダウンタイムを最小限に抑えます。
- 迅速なデプロイ: CI/CDパイプラインとの統合により、新しいAIモデルや機能のデプロイを迅速化し、市場投入までの時間を短縮します。
- 再現性と可視性: AIモデルのバージョン管理、データパイプラインの追跡、監査ログの記録により、システムの再現性と可視性を高めます。
KubernetesによるAIリソース管理
Kubernetesは、コンテナ化されたアプリケーションを管理するためのオープンソースのオーケストレーションプラットフォームです。AIモデルのデプロイと運用において、リソース管理、スケーリング、耐障害性を提供します。
GPUリソースの効率的な活用
AIモデルの学習や推論には、GPUが不可欠です。Kubernetesでは、GPUリソースを効率的に管理し、複数のPod間で共有することができます。
以下の例では、NVIDIA GPUを要求するPodを定義しています。
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: gpu-container
image: nvidia/cuda:11.0-base
resources:
limits:
nvidia.com/gpu: 1
Kubernetesは、利用可能なGPUリソースを自動的に割り当て、Podを適切なノードにスケジュールします。また、GPUの使用状況を監視し、リソースの最適化を支援します。
カスタムリソース定義(CRD)によるAIワークロード管理
Kubernetesのカスタムリソース定義(CRD)を利用することで、AI固有のワークロード(モデル学習、推論サービスなど)を抽象化し、管理することができます。
例えば、`ModelDeployment`というCRDを定義し、AIモデルのデプロイメントを表現することができます。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: modeldeployments.example.com
spec:
group: example.com
versions:
- name: v1alpha1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
modelName:
type: string
modelVersion:
type: string
replicas:
type: integer
scope: Namespaced
names:
plural: modeldeployments
singular: modeldeployment
kind: ModelDeployment
shortNames:
- md
このCRDを使用することで、AIモデルのデプロイメントを宣言的に定義し、Kubernetesコントローラによって自動的に管理することができます。
ArgoCDによるGitOpsとAIモデルのデプロイ
ArgoCDは、Kubernetes向けの宣言的なGitOpsツールです。Gitリポジトリに定義されたアプリケーションの状態をKubernetesクラスタに同期し、自動的なデプロイメントとロールバックを実現します。
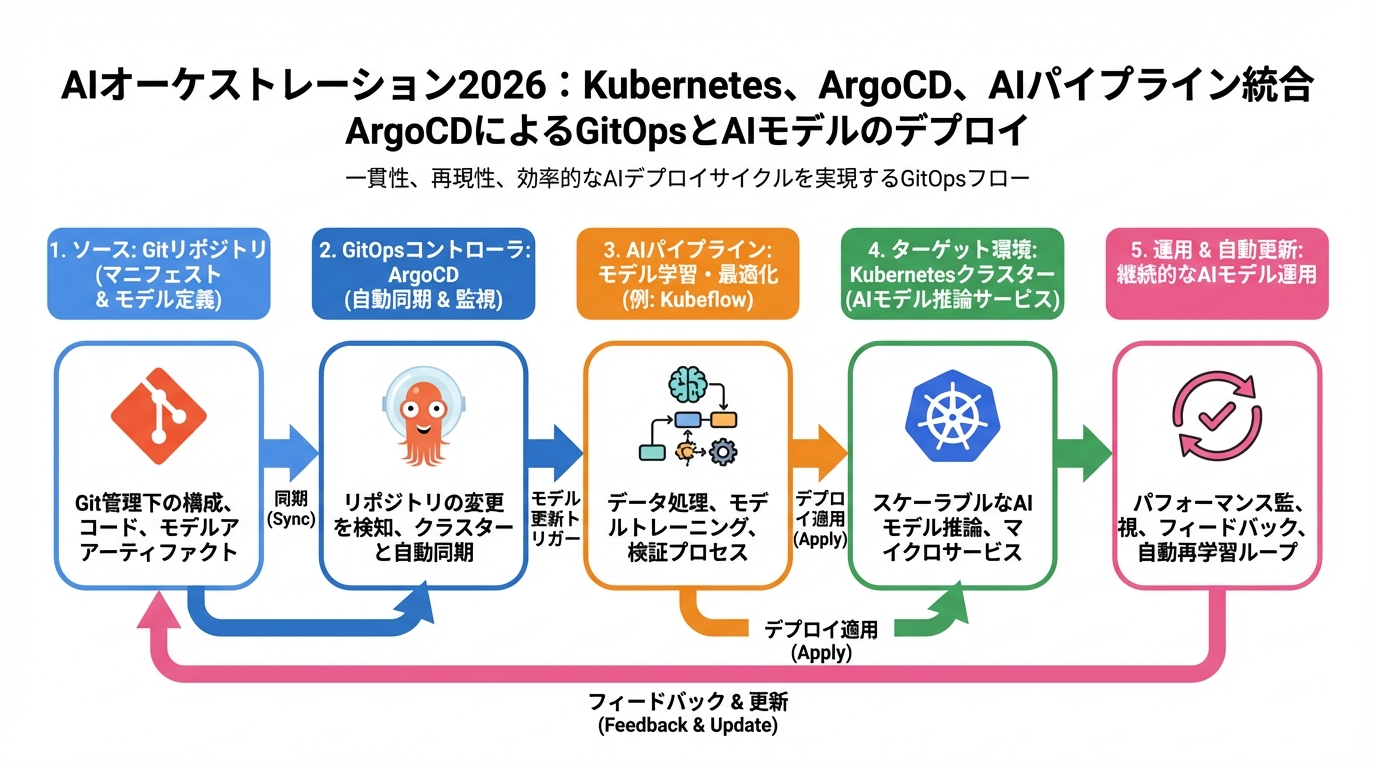
GitOpsによる継続的デリバリー
GitOpsとは、アプリケーションの構成とインフラストラクチャのコードをGitリポジトリで管理し、そのリポジトリを信頼できる唯一の情報源とする運用手法です。ArgoCDは、GitOpsの原則に従い、Gitリポジトリに定義されたアプリケーションの状態をKubernetesクラスタに自動的に同期します。
AIモデルのデプロイメントにおいても、モデルのバージョン、デプロイメント設定、リソース要件などをGitリポジトリで管理し、ArgoCDによって自動的にデプロイすることができます。
CanaryデプロイメントとBlue/Greenデプロイメント
ArgoCDは、CanaryデプロイメントやBlue/Greenデプロイメントなどの高度なデプロイメント戦略をサポートしています。これらの戦略を利用することで、新しいAIモデルを段階的にリリースし、リスクを最小限に抑えることができます。
Canaryデプロイメントでは、新しいバージョンのAIモデルを一部のユーザーにのみ公開し、そのパフォーマンスを監視します。問題がなければ、徐々にトラフィックを新しいバージョンに移行します。
Blue/Greenデプロイメントでは、新しいバージョンのAIモデルを別の環境(Green)にデプロイし、テストを行います。テストが完了したら、トラフィックをGreen環境に切り替えます。
AIパイプラインとの統合
AIオーケストレーションは、AIパイプライン(データ収集、データ加工、モデル学習、モデル評価など)との連携が不可欠です。AIパイプラインをKubernetes上で実行し、ArgoCDによって管理することで、AIモデルのライフサイクル全体を自動化することができます。
Kubeflow PipelinesによるAIワークフロー自動化
Kubeflow Pipelinesは、Kubernetes上で実行されるAIワークフローを定義および実行するためのプラットフォームです。データ処理、モデル学習、モデル評価などの各ステップをコンポーネントとして定義し、それらをパイプラインとして結合することができます。
import kfp
from kfp import dsl
@dsl.component
def preprocess_data(input_data_path: str, output_data_path: str):
pass
@dsl.component
def train_model(preprocessed_data_path: str, model_path: str):
pass
@dsl.pipeline(name='AI Pipeline')
def ai_pipeline(input_data_path: str):
preprocessed_data = preprocess_data(input_data_path=input_data_path)
model = train_model(preprocessed_data_path=preprocessed_data.outputs['output_data_path'])
if __name__ == '__main__':
kfp.compiler.Compiler().compile(ai_pipeline, 'ai_pipeline.yaml')
Kubeflow Pipelinesで定義されたパイプラインは、Kubernetes上で実行され、各コンポーネントはコンテナとして実行されます。ArgoCDと連携することで、パイプラインのバージョン管理、トリガー、モニタリングを自動化することができます。
Seldon Coreによる推論サーバのデプロイ
Seldon Coreは、Kubernetes上でAIモデルをデプロイするためのオープンソースプラットフォームです。モデルサーバ、ロードバランサ、モニタリングツールなどを統合し、推論サービスの構築を容易にします。
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: my-model
spec:
predictors:
- name: default
graph:
implementation: TENSORFLOW_SERVER
modelUri: gs://my-bucket/my-model
replicas: 1
Seldon Coreは、様々なモデル形式(TensorFlow、PyTorch、scikit-learnなど)をサポートし、REST APIまたはgRPC APIで推論サービスを提供します。ArgoCDと連携することで、モデルのデプロイメントとバージョン管理を自動化することができます。
まとめ:AIオーケストレーションでAIサービスの未来を切り拓く
本記事では、Kubernetes、ArgoCD、AIパイプラインといった主要なツールを統合し、AIオーケストレーションを実践するための技術とベストプラクティスを紹介しました。AIオーケストレーションは、AIモデルのライフサイクル全体を効率的に管理・自動化し、コスト削減、安定稼働、迅速なデプロイを実現するための鍵となります。
2026年以降、AI技術はますます進化し、その応用範囲は広がり続けるでしょう。AIオーケストレーションの重要性はますます高まり、AIサービスの未来を切り拓くための不可欠な要素となるでしょう。


