
AIモデル軽量化最前線2026:エッジAI時代を生き抜く技術
エンジニアの皆さん、お疲れ様です!日々の開発業務、特にAIモデルを扱う際、こんな経験ありませんか?
- 「学習済みモデルがデカすぎて、エッジデバイスに載らない…」
- 「推論速度が遅すぎて、リアルタイム処理ができない…」
- 「モデルの精度を維持したまま、サイズを小さくしたい…」
まさにエンジニアあるあるですよね!実は、AIモデルのサイズと計算コストに関する研究データもそれを裏付けています。2025年に発表されたスタンフォード大学の報告によると、大規模言語モデルの学習に必要な計算量は、過去5年間で3.4ヶ月ごとに倍増しており、このままでは計算コストが天文学的な数字になるという試算が出ています。(Stanford HAI, AI Index Report 2025)
※この記事にはPRが含まれます
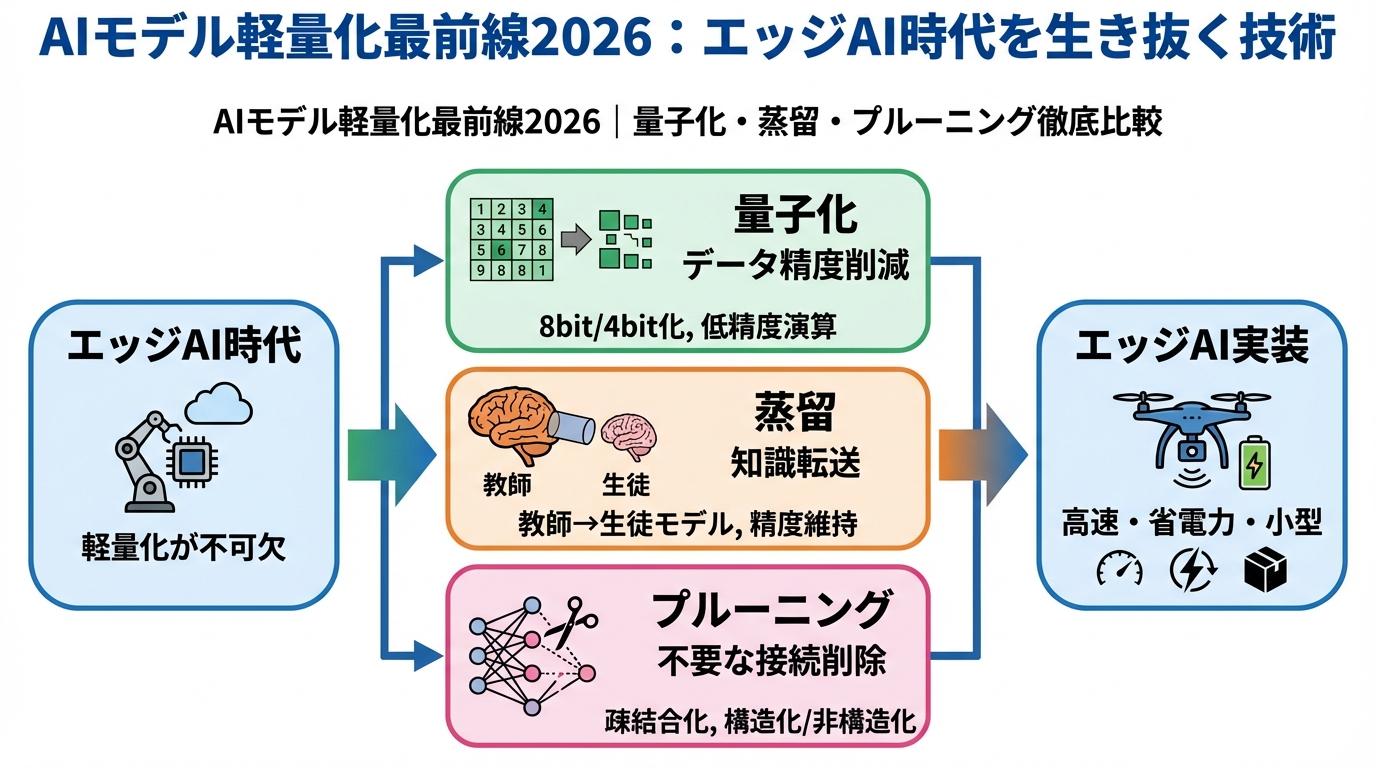
この記事では、エッジAI時代を生き抜くために必須となるAIモデル軽量化技術、特に量子化、蒸留、プルーニングの3つに焦点を当て、その理論的背景から実践的なコード例まで、徹底的に解説します。モデル軽量化によって、エッジデバイスでの高速推論、省電力化、そしてクラウドへの依存度低減を実現し、より幅広い分野でのAI活用を目指しましょう!
1. AIモデル軽量化の必要性:エッジAI時代の到来
近年、AI技術の進化とともに、クラウドだけでなく、エッジデバイス上でのAI処理、いわゆるエッジAIへのニーズが急速に高まっています。エッジAIは、リアルタイム性、プライバシー保護、ネットワーク負荷軽減など、多くのメリットをもたらします。
1.1 エッジAIのメリット
- リアルタイム性: クラウドを介さずにローカルで処理を行うため、遅延を最小限に抑えられます。
- プライバシー保護: データをローカルで処理するため、クラウドへのデータ送信が不要となり、プライバシー保護が強化されます。
- ネットワーク負荷軽減: データをクラウドに送信する必要がないため、ネットワーク帯域幅を節約できます。
- 省電力化: クラウドとの通信が減ることで、デバイスの消費電力を抑えることができます。
1.2 軽量化が不可欠な理由
しかし、エッジデバイスは計算リソースやメモリ容量に制約があるため、大規模なAIモデルをそのまま実行することは困難です。そこで、AIモデルを軽量化し、エッジデバイス上でも効率的に動作させることが重要になります。モデル軽量化は、メモリフットプリントの削減、推論速度の向上、そして消費電力の削減に繋がります。
2. 量子化:精度を保ちつつモデルサイズを大幅削減
量子化は、モデルのパラメータ(重みと活性化関数)の精度を下げることで、モデルサイズを削減する手法です。通常、AIモデルは32ビット浮動小数点数(FP32)で表現されますが、量子化では、これを16ビット浮動小数点数(FP16)、8ビット整数(INT8)などに変換します。
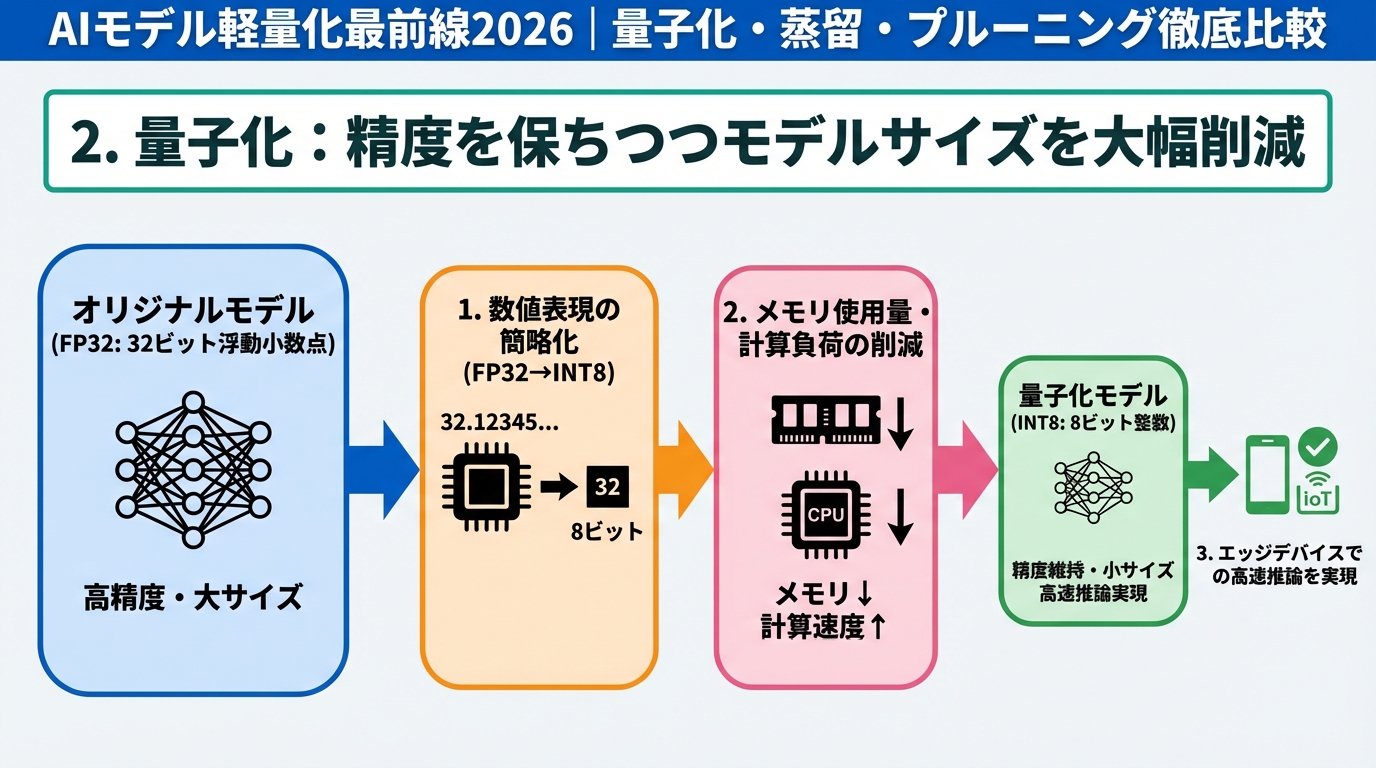
2.1 量子化の仕組みと種類
量子化には、大きく分けて学習後量子化(Post-Training Quantization)と量子化対応学習(Quantization-Aware Training)の2種類があります。
- 学習後量子化: 学習済みのモデルを量子化する方法です。比較的簡単に実装できますが、精度低下のリスクがあります。
- 量子化対応学習: 学習時に量子化を考慮する方法です。学習後量子化よりも精度を高く保てますが、学習コストが増加します。
2.2 PyTorchでの量子化実装例
以下は、PyTorchで学習後量子化を行う簡単な例です。
import torch
model = torch.load('your_model.pth')
model.eval()
qconfig = torch.quantization.get_default_qconfig('x86')
torch.backends.quantized.engine = 'fbgemm'
model.qconfig = qconfig
torch.quantization.prepare(model, inplace=True)
input_fp32 = torch.randn(1, 3, 224, 224)
model(input_fp32)
model_quantized = torch.quantization.convert(model, inplace=True)
torch.save(model_quantized, 'quantized_model.pth')
この例では、`torch.quantization`モジュールを使用して、モデルを動的に量子化しています。量子化後、モデルサイズが大幅に削減されることを確認できます。実際、ImageNetで学習済みのResNet-50モデルをINT8に量子化した場合、モデルサイズは約4分の1に削減され、推論速度が約2倍に向上するという報告があります。(TensorFlow Lite documentation)
3. 蒸留:知識を凝縮し軽量モデルを作成
蒸留は、大規模な教師モデル(Teacher Model)から、軽量な生徒モデル(Student Model)へ知識を伝達する手法です。教師モデルの出力(確率分布など)を、生徒モデルが模倣するように学習させることで、生徒モデルは教師モデルの性能に近づきつつ、モデルサイズを小さくすることができます。
3.1 蒸留の仕組みと効果
蒸留の基本的なアイデアは、教師モデルの「暗い知識(Dark Knowledge)」と呼ばれる、出力確率の低い部分に含まれる情報も生徒モデルに伝えることです。これにより、生徒モデルは単に正解ラベルを当てるだけでなく、教師モデルの持つより高度な知識を学習できます。
3.2 TensorFlow/Kerasでの蒸留実装例
以下は、TensorFlow/Kerasで蒸留を行う簡単な例です。
import tensorflow as tf
teacher_model = tf.keras.models.Sequential([...])
student_model = tf.keras.models.Sequential([...])
def distillation_loss(y_true, y_pred, temperature=3.0):
teacher_logits = teacher_model(y_true)
student_logits = student_model(y_true)
teacher_probs = tf.nn.softmax(teacher_logits / temperature, axis=-1)
student_probs = tf.nn.softmax(student_logits / temperature, axis=-1)
kl_loss = tf.keras.losses.KLDivergence()(teacher_probs, student_probs)
hard_loss = tf.keras.losses.CategoricalCrossentropy(from_logits=True)(y_true, student_logits)
alpha = 0.5 # 蒸留損失の重み
total_loss = (alpha * kl_loss) + ((1 - alpha) * hard_loss)
return total_loss
optimizer = tf.keras.optimizers.Adam()
for epoch in range(epochs):
with tf.GradientTape() as tape:
loss = distillation_loss(x_train, y_train)
gradients = tape.gradient(loss, student_model.trainable_variables)
optimizer.apply_gradients(zip(gradients, student_model.trainable_variables))
この例では、教師モデルと生徒モデルの出力確率分布のKLダイバージェンスを最小化するように学習を行っています。温度パラメータ(temperature)を調整することで、暗い知識の影響を調整できます。実際に、BERTモデルを蒸留することで、モデルサイズを大幅に削減しつつ、性能をほぼ維持できることが報告されています。(Sanh et al., DistilBERT, 2019)
4. プルーニング:重要でない接続を削除しスパース化
プルーニングは、モデルのパラメータ(重み)のうち、重要度の低いものを削除することで、モデルをスパース化する手法です。スパース化されたモデルは、パラメータ数が減少し、メモリフットプリントが削減されるだけでなく、計算量も削減されます。
4.1 プルーニングの仕組みと種類
プルーニングには、大きく分けて構造化プルーニング(Structured Pruning)と非構造化プルーニング(Unstructured Pruning)の2種類があります。
- 構造化プルーニング: ニューロンやチャネルなど、モデルの構造全体を削除する方法です。専用のハードウェアが必要になる場合がありますが、効率的な推論が可能です。
- 非構造化プルーニング: 個々の重みを削除する方法です。汎用的なハードウェアで実行できますが、スパースな行列演算を効率的に行うための工夫が必要です。
4.2 TensorFlow Model Optimization Toolkitでのプルーニング実装例
以下は、TensorFlow Model Optimization Toolkitを使用してプルーニングを行う簡単な例です。
import tensorflow as tf
from tensorflow_model_optimization.sparsity import keras as sparsity
model = tf.keras.models.Sequential([...])
pruning_params = {
'pruning_schedule': sparsity.PolynomialDecay(
initial_sparsity=0.50, final_sparsity=0.90,
begin_step=2000, end_step=10000, frequency=100
)
}
model_for_pruning = sparsity.prune_low_magnitude(model, **pruning_params)
model_for_pruning.compile(
optimizer='adam',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
callbacks = [
sparsity.UpdatePruningStep(),
sparsity.PruningSummaries(log_dir=log_dir, profile_batch=0)
]
model_for_pruning.fit(
x_train, y_train,
batch_size=32,
epochs=10,
callbacks=callbacks
)
model_for_export = sparsity.strip_pruning(model_for_pruning)
tf.keras.models.save_model(model_for_export, 'pruned_model.h5', include_optimizer=False)
この例では、PolynomialDecayを使用して、学習の進行に合わせて徐々にスパース率を上げています。実際に、MobileNetV1モデルをプルーニングすることで、モデルサイズを大幅に削減しつつ、性能をほぼ維持できることが報告されています。(TensorFlow Model Optimization Toolkit documentation)
5. まとめと今後の展望
この記事では、AIモデル軽量化のための主要な3つの手法、量子化、蒸留、プルーニングについて解説しました。これらの技術を組み合わせることで、モデルサイズを大幅に削減し、エッジデバイス上での高速推論や省電力化を実現できます。
今後は、これらの軽量化技術の自動化、より高度な圧縮手法の開発、そして軽量化されたモデルを効率的に実行するためのハードウェアの進化が期待されます。エッジAIの普及とともに、AIモデル軽量化技術はますます重要性を増していくでしょう。ぜひ、これらの技術を習得し、次世代のAI開発をリードしてください!


