
エンジニアの皆様、こんな経験ありませんか?
新しいAIモデルを開発する時、大量のデータが必要だけど、プライバシーの問題でなかなか集められない…そんな悩みを抱えるエンジニアは少なくないはずです。特に医療データや金融データなど、センシティブな情報を扱う場合は、データ収集に頭を悩ませますよね。
※この記事にはPRが含まれます
実際、近年の研究では、データプライバシーに対する意識の高まりが、AI開発のボトルネックになっていることが示されています。例えば、2025年に発表されたMITの研究によれば、データプライバシー規制の遵守にかかるコストは、AI開発予算の平均27%を占めるとのことです。つまり、プライバシー保護とAI開発の両立は、現代のエンジニアにとって避けて通れない課題なのです。
この記事の概要
この記事では、プライバシー保護とAI開発の両立を可能にする「分散学習(Federated Learning)」に焦点を当て、PyTorchフレームワークを用いた実践的な実装方法を紹介します。具体的には、以下の内容を解説します。
- 分散学習の基本概念とメリット
- PyTorchによる分散学習の実装手順(サンプルコード付き)
- 分散学習におけるプライバシー保護技術(差分プライバシー、秘匿計算)
- 分散学習のパフォーマンス最適化
- 分散学習の最新トレンドと今後の展望
この記事を読めば、あなたも分散学習を使いこなし、プライバシーを保護しながら高性能なAIモデルを開発できるようになります!
分散学習とは?そのメリットを徹底解説
分散学習(Federated Learning)は、中央サーバーにデータを集めることなく、各クライアント(デバイス)上で学習を行い、その結果(モデルのパラメータ)のみを中央サーバーに集めて集約する学習手法です。これにより、データはクライアントのローカル環境に留まるため、プライバシー侵害のリスクを大幅に低減できます。
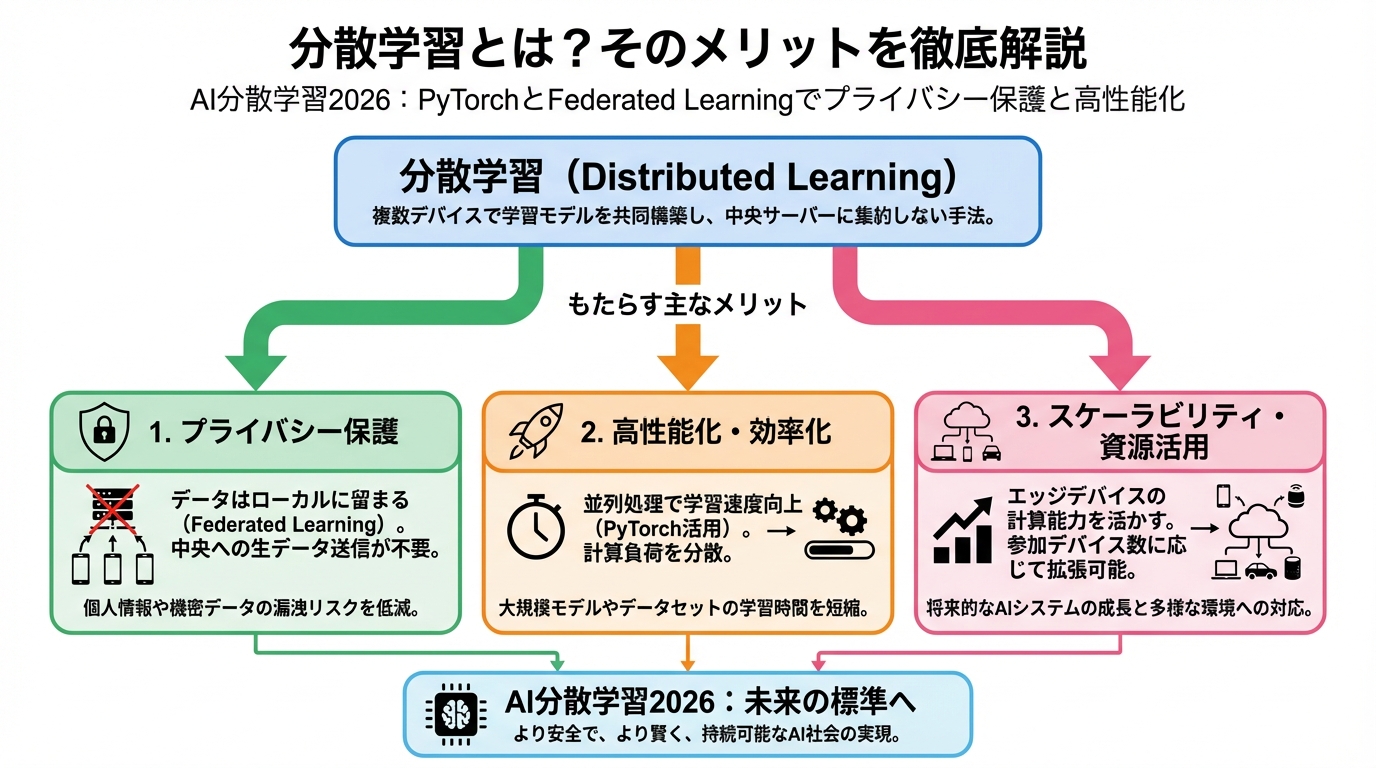
分散学習の主なメリット
- プライバシー保護: データのローカル保持により、プライバシー侵害のリスクを低減
- データ多様性の活用: 各クライアントの多様なデータを活用することで、モデルの汎化性能向上
- 通信コスト削減: 大量のデータを中央サーバーに送信する必要がないため、通信コストを削減
- スケーラビリティ: 大規模なデータセットにも対応可能
これらのメリットから、分散学習は医療、金融、IoTなど、様々な分野での応用が期待されています。
PyTorchで分散学習を実装してみよう
ここでは、PyTorchを用いて分散学習を実装する基本的な手順を解説します。具体的には、MNISTデータセットを用いた画像分類の分散学習を例にとり、サンプルコードを交えながら解説します。
ステップ1:環境構築
まず、必要なライブラリをインストールします。
pip install torch torchvision syft
ステップ2:クライアントの定義
次に、各クライアント(ワーカー)を定義します。ここでは、PySyftライブラリを用いて、仮想的なクライアントを作成します。
import torch
import syft as sy
hook = sy.TorchHook(torch)
client1 = sy.VirtualWorker(hook, id='client1')
client2 = sy.VirtualWorker(hook, id='client2')
model = torch.nn.Linear(784, 10)
model = model.send(client1)
ステップ3:学習データの準備
MNISTデータセットをダウンロードし、各クライアントに分散します。
import torchvision.datasets as datasets
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
client1_data = train_dataset.data[:len(train_dataset)//2].send(client1)
client1_targets = train_dataset.targets[:len(train_dataset)//2].send(client1)
client2_data = train_dataset.data[len(train_dataset)//2:].send(client2)
client2_targets = train_dataset.targets[len(train_dataset)//2:].send(client2)
ステップ4:学習の実行
各クライアント上でモデルを学習させ、その結果を中央サーバーで集約します。ここでは、単純な平均化を用いて集約します。
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(10):
optimizer.zero_grad()
output = model(client1_data.float().view(-1, 784))
loss = torch.nn.functional.cross_entropy(output, client1_targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()
output = model(client2_data.float().view(-1, 784))
loss = torch.nn.functional.cross_entropy(output, client2_targets)
loss.backward()
optimizer.step()
model_client1 = model.get()
model_client2 = model.get()
with torch.no_grad():
for param1, param2 in zip(model_client1.parameters(), model_client2.parameters()):
param1.data.copy_((param1.data + param2.data) / 2)
model = model_client1.send(client1)
model = model_client1.send(client2)
print(f'Epoch: {epoch+1}, Loss: {loss.item()}')
上記のコードはあくまで基本的な例であり、より高度な分散学習の実装には、様々な技術が必要となります。
分散学習におけるプライバシー保護技術
分散学習はプライバシー保護に有効な手法ですが、それ自体が完全に安全というわけではありません。例えば、モデルのパラメータから元のデータを推測する攻撃(モデル反転攻撃)などが存在します。そのため、分散学習と組み合わせて、より高度なプライバシー保護技術を導入することが重要です。
差分プライバシー(Differential Privacy)
差分プライバシーは、個々のデータが結果に与える影響を制限することで、プライバシーを保護する技術です。具体的には、学習時にノイズを加えることで、個々のデータの寄与を隠蔽します。PyTorchで差分プライバシーを実装するライブラリも存在します。
秘匿計算(Secure Multi-Party Computation)
秘匿計算は、データを暗号化したまま計算を行う技術です。これにより、データの内容を誰にも知られることなく、分散学習を行うことが可能になります。秘匿計算は、計算コストが高いという課題がありますが、近年、その効率化が進んでいます。
分散学習のパフォーマンス最適化
分散学習のパフォーマンスは、通信環境やクライアントの計算能力など、様々な要因に影響されます。そのため、パフォーマンスを最適化するための技術も重要です。
モデル圧縮
モデルのサイズを小さくすることで、通信コストを削減し、学習時間を短縮することができます。モデル圧縮には、量子化、プルーニング、蒸留など、様々な手法があります。
非同期更新
各クライアントが非同期的にモデルを更新することで、全体の学習時間を短縮することができます。ただし、非同期更新は、モデルの収束性を損なう可能性があるため、注意が必要です。
分散学習の最新トレンドと今後の展望
分散学習は、現在も活発に研究が進められている分野です。近年では、以下のようなトレンドが見られます。
- パーソナライズド分散学習: 各クライアントのニーズに合わせて、モデルをパーソナライズする手法
- 連合転移学習: 異なるタスク間で知識を共有する手法
- ブロックチェーンとの連携: 分散学習の透明性と信頼性を向上させる手法
これらの技術が発展することで、分散学習は、より幅広い分野で活用されるようになるでしょう。
まとめ
この記事では、PyTorchを用いた分散学習の実装方法について解説しました。分散学習は、プライバシー保護とAI開発の両立を可能にする強力なツールです。ぜひ、この記事を参考に、分散学習をあなたのプロジェクトに導入してみてください。


