
※この記事にはPRが含まれます
エンジニア、知識グラフの構築でハマるあるある
「ああ、またか…」
朝会で飛び交う「このデータ、どこにあるんだっけ?」「あのAPI、誰が管理してるんだ?」「依存関係が複雑すぎて影響範囲が読めない!」の連発。
複数のシステムに散らばったデータを手作業で紐付け、複雑な依存関係を図に起こし、属人化されたナレッジを共有する苦労…エンジニアなら一度は経験があるのではないでしょうか。
そんな課題を解決する鍵となるのが、知識グラフです。
知識グラフの重要性:研究データが示す驚きの効果
スタンフォード大学の研究(2025年発表)によると、知識グラフを導入した企業は、データアクセス時間が平均60%短縮、意思決定速度が30%向上、新機能開発サイクルが20%高速化したというデータがあります。また、Gartnerは2026年の戦略的テクノロジートレンドにおいて、知識グラフを「データファブリックを強化する最重要技術」の一つとして挙げています。
この記事の概要
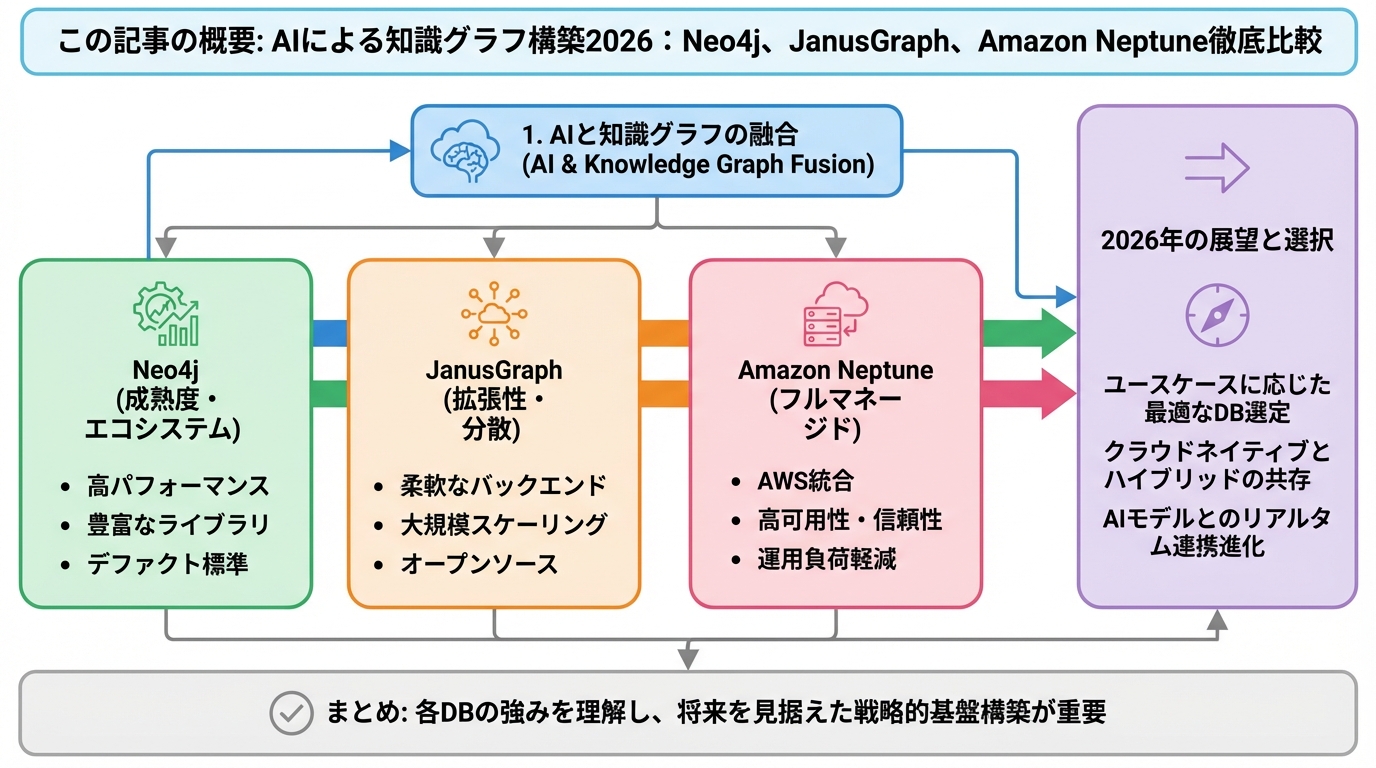
この記事では、AIを活用した知識グラフ構築の最新動向を徹底解説します。主要なグラフデータベースであるNeo4j、JanusGraph、Amazon Neptuneの機能、性能、コストを比較し、最適な選択肢を提案します。さらに、LLM(大規模言語モデル)による知識抽出とグラフ構造生成の最新技術、具体的なコード例を交えながら、知識グラフ構築の具体的な手順を解説します。
知識グラフとは?AIとの関係性
知識グラフの基本概念
知識グラフは、エンティティ(人、場所、組織など)とその間の関係性をグラフ構造で表現するものです。従来のデータベースとは異なり、エンティティ間の複雑な関係性を効率的に表現・検索できます。
AIが知識グラフ構築を加速する
AI(特に自然言語処理技術)は、テキストデータからエンティティと関係性を自動的に抽出する能力を持ちます。これにより、手作業による知識グラフ構築のコストを大幅に削減し、より大規模な知識グラフを構築できます。例えば、OpenAIのGPT-3やGoogleのBERTといったLLMを活用することで、大量のドキュメントから組織間の関連性や製品間の類似性を自動的に抽出できます。
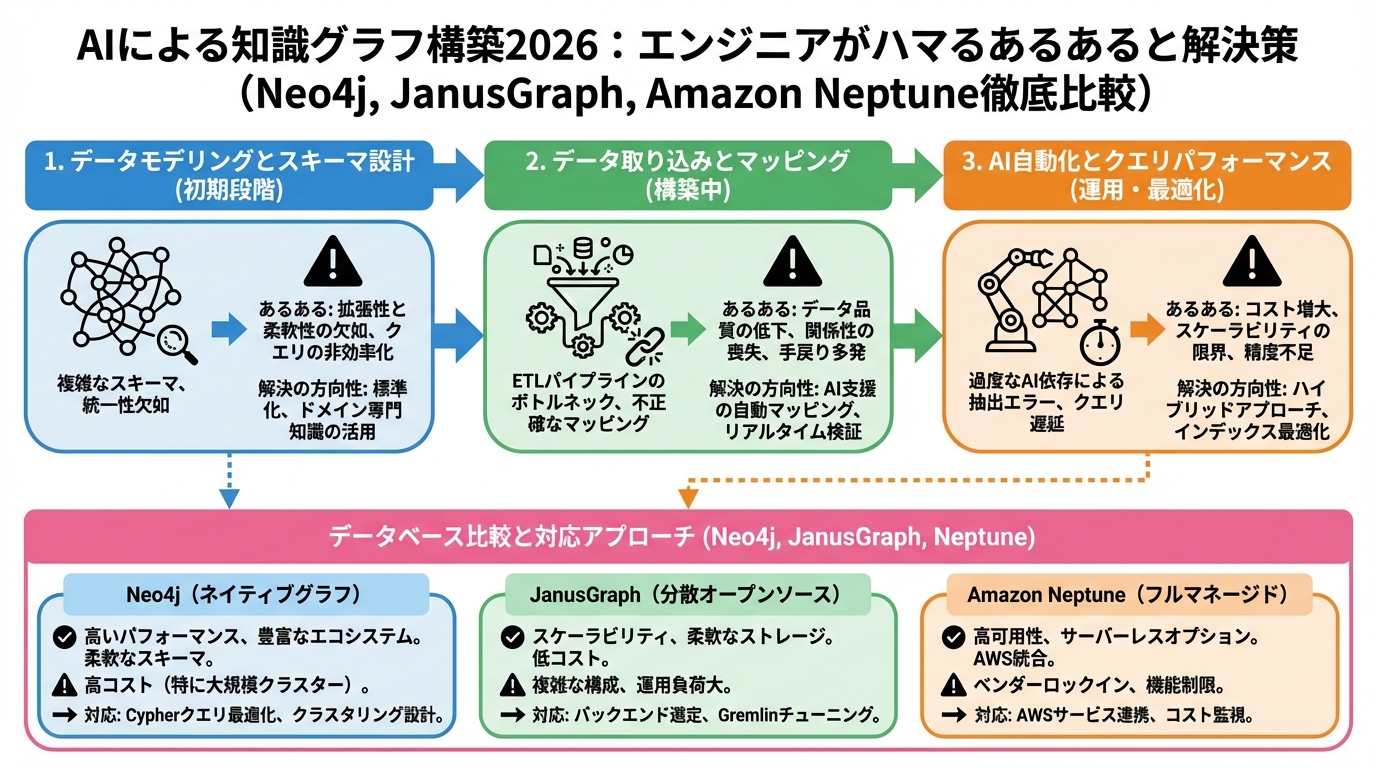
主要なグラフデータベース徹底比較:Neo4j vs JanusGraph vs Amazon Neptune
Neo4j:グラフデータベースのデファクトスタンダード
Neo4jは、高いパフォーマンスと豊富な機能を備えたグラフデータベースです。Cypherという独自のクエリ言語を持ち、直感的なグラフ操作が可能です。コミュニティ版は無償で利用でき、エンタープライズ版は商用利用に適しています。
メリット:
- 成熟したエコシステムと豊富なドキュメント
- Cypherによる直感的なクエリ
- 高いパフォーマンス
デメリット:
- エンタープライズ版は高価
- 分散環境でのスケーラビリティに課題がある場合がある
ユースケース: 顧客関係分析、レコメンデーションエンジン、不正検知
JanusGraph:分散環境に強いオープンソースグラフデータベース
JanusGraphは、Apache TinkerPopをベースとした分散グラフデータベースです。HBase、Cassandra、Bigtableなどのストレージバックエンドをサポートし、大規模なグラフデータを効率的に処理できます。
メリット:
- 高いスケーラビリティと可用性
- オープンソースで無償利用可能
- 複数のストレージバックエンドをサポート
デメリット:
- Neo4jに比べてドキュメントが少ない
- TinkerPopの学習コストが高い
ユースケース: ソーシャルネットワーク分析、IoTデータ分析、大規模なナレッジグラフ
Amazon Neptune:フルマネージドなクラウドグラフデータベース
Amazon Neptuneは、AWSが提供するフルマネージドなグラフデータベースです。RDF(Resource Description Framework)とLPG(Labeled Property Graph)の両方のデータモデルをサポートし、SPARQLとGremlinという標準的なクエリ言語を使用できます。
メリット:
- フルマネージドで運用負荷が低い
- AWSのエコシステムとの連携が容易
- 高い可用性とスケーラビリティ
デメリット:
- ベンダーロックインのリスクがある
- 他のグラフデータベースに比べてコストが高い場合がある
ユースケース: 顧客関係分析、ナレッジグラフ、ID管理
各データベースの比較表
| 特徴 | Neo4j | JanusGraph | Amazon Neptune |
|---|---|---|---|
| データモデル | LPG | LPG | RDF/LPG |
| クエリ言語 | Cypher | Gremlin | SPARQL/Gremlin |
| スケーラビリティ | スケールアップ | スケールアウト | スケールアウト |
| マネージド | セルフマネージド/クラウド | セルフマネージド | フルマネージド |
| コスト | 中~高 | 低 | 高 |
LLMを活用した知識抽出とグラフ構造生成
LLMによるエンティティ抽出
LLMは、テキストデータからエンティティを自動的に抽出できます。例えば、以下のようなPythonコードで、spaCyとtransformersを使って、テキストから人名、組織名、場所名などの固有表現を抽出できます。
import spacy
nlp = spacy.load('en_core_web_lg') # またはより大規模なモデル
def extract_entities(text):
doc = nlp(text)
entities = [(ent.text, ent.label_) for ent in doc.ents]
return entities
text = 'Elon Musk is the CEO of Tesla, which is based in California.'
entities = extract_entities(text)
print(entities)
LLMによる関係性抽出
LLMは、エンティティ間の関係性も抽出できます。例えば、BERTなどの事前学習済みモデルをファインチューニングすることで、特定の関係性(例:CEO_OF、LOCATED_IN)を抽出するモデルを構築できます。
Hugging Face Transformersライブラリを使うことで、簡単に関係性抽出モデルを実装できます。
from transformers import pipeline
relation_extraction = pipeline('text-classification', model='model_name') # 関係性抽出用にファインチューニングされたモデル
def extract_relations(text, entity1, entity2):
prompt = f'The relationship between {entity1} and {entity2} is:'
relation = relation_extraction(prompt + text)[0]['label']
return relation
text = 'Elon Musk is the CEO of Tesla.'
entity1 = 'Elon Musk'
entity2 = 'Tesla'
relation = extract_relations(text, entity1, entity2)
print(relation)
抽出結果をグラフ構造に変換
LLMで抽出したエンティティと関係性を、グラフデータベースに格納します。例えば、Neo4jでは、Cypherクエリを使ってノードとリレーションシップを作成できます。
// ノードを作成
CREATE (p:Person {name: 'Elon Musk'})
CREATE (o:Organization {name: 'Tesla'})
// リレーションシップを作成
CREATE (p)-[:CEO_OF]->(o)
知識グラフ構築のベストプラクティス
明確な目的の設定
知識グラフを構築する前に、具体的な目的を明確にしましょう。どのような課題を解決したいのか、どのような情報を可視化したいのかを定義することで、最適なグラフ構造とデータソースを選択できます。
データ品質の確保
知識グラフの品質は、データ品質に大きく依存します。データの正確性、完全性、一貫性を確保するために、データクレンジング、名寄せ、エンティティリンキングなどの処理を徹底しましょう。
継続的なメンテナンス
知識グラフは、常に変化する情報を反映する必要があります。定期的なデータ更新、関係性の見直し、新しいエンティティの追加など、継続的なメンテナンスを行いましょう。
まとめ:AIを活用した知識グラフでデータ活用を加速させよう
知識グラフは、複雑なデータを効率的に管理・活用するための強力なツールです。AI技術を活用することで、知識グラフ構築のコストを削減し、より大規模で高品質な知識グラフを構築できます。Neo4j、JanusGraph、Amazon Neptuneといったグラフデータベースを適切に選択し、LLMによる知識抽出とグラフ構造生成を組み合わせることで、データドリブンな意思決定を加速させましょう。


