
エンジニアなら共感?障害対応の苦悩
「またか…」アラートメールで目が覚める午前3時。見慣れた監視ツールのダッシュボードを開くと、CPU使用率が異常な数値を示している。原因特定に数時間。結局、メモリリークが原因だった、なんて経験ありませんか?
障害対応はエンジニアの宿命ですが、その負荷は決して小さくありません。Google Researchの2025年の調査によれば、ソフトウェアエンジニアは週平均8時間、デバッグと障害対応に費やしているとのことです。この時間を削減できれば、より創造的な業務に集中できるはずです。
※この記事にはPRが含まれます
そこで、この記事では、AIを活用したモニタリングの最前線について解説します。異常検知から根本原因の特定まで、AIがいかに効率的かつ効果的に障害対応を支援できるのか、具体的な手法とコード例を交えながらご紹介します。
なぜAIモニタリングが重要なのか?
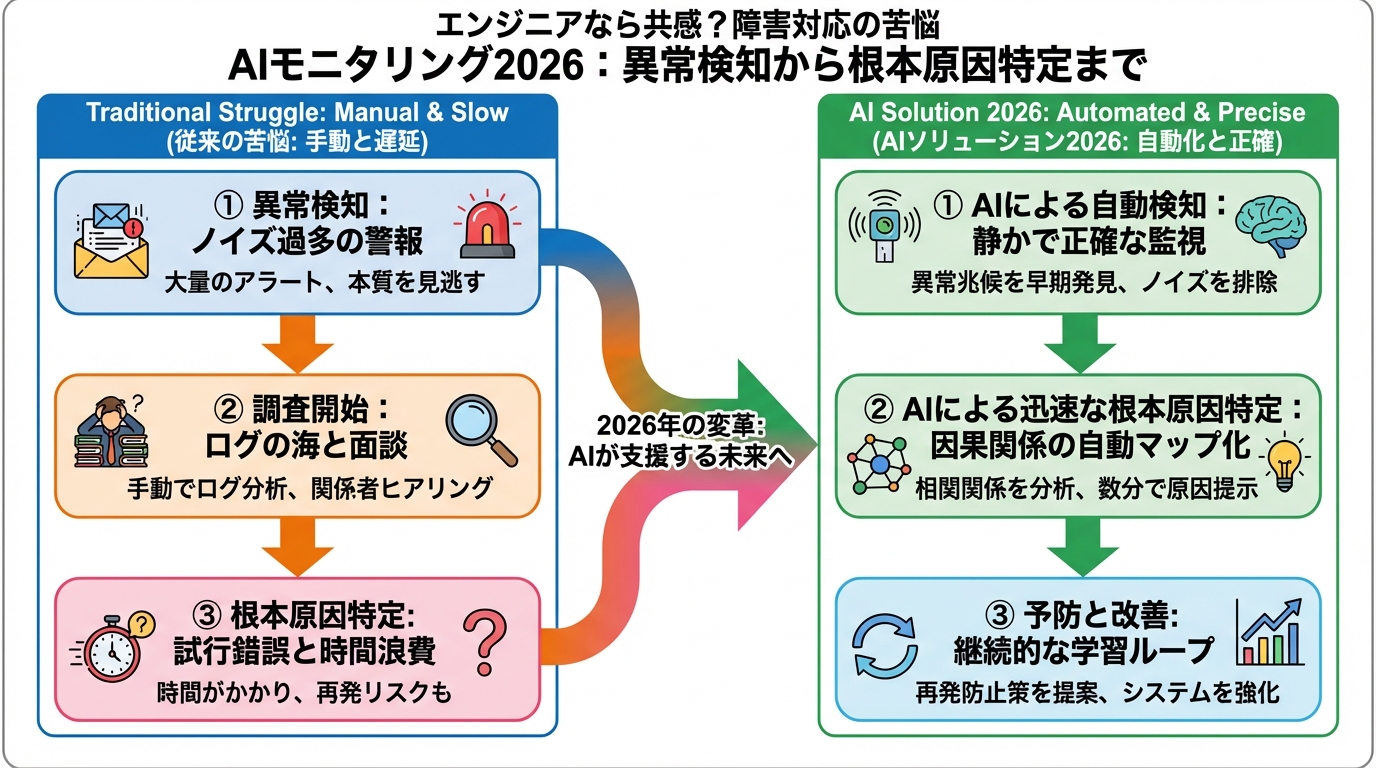
従来のモニタリングシステムは、設定された閾値に基づいてアラートを発報するものが主流でした。しかし、現代の複雑なシステムにおいては、これらの手法では限界があります。例えば、マイクロサービスアーキテクチャでは、数百、数千のサービスが連携しており、一つのサービスのわずかな異常が、連鎖的に他のサービスに影響を及ぼす可能性があります。このような複雑な依存関係を、人間の手で網羅的に監視することは困難です。
AIモニタリングは、機械学習アルゴリズムを用いて、システムの正常な動作パターンを学習し、逸脱を検知します。これにより、従来のモニタリングシステムでは見逃していた潜在的な問題を早期に発見し、障害の発生を未然に防ぐことが可能になります。
従来のモニタリングの課題
- 閾値設定の難しさ:システムの変化に合わせて常に調整が必要
- 誤検知の多さ:些細な変動でもアラートが発報され、ノイズとなる
- 根本原因の特定困難:アラートだけでは、問題の根本原因を特定できない
AIモニタリングのメリット
- 異常検知の精度向上:過去のデータから学習し、正常な範囲を自動で判断
- アラートの絞り込み:ノイズとなるアラートを抑制し、重要なアラートに集中できる
- 根本原因の特定支援:複数の指標を分析し、問題の根本原因を特定する
AIモニタリングの主要技術
AIモニタリングには、主に以下の技術が活用されています。
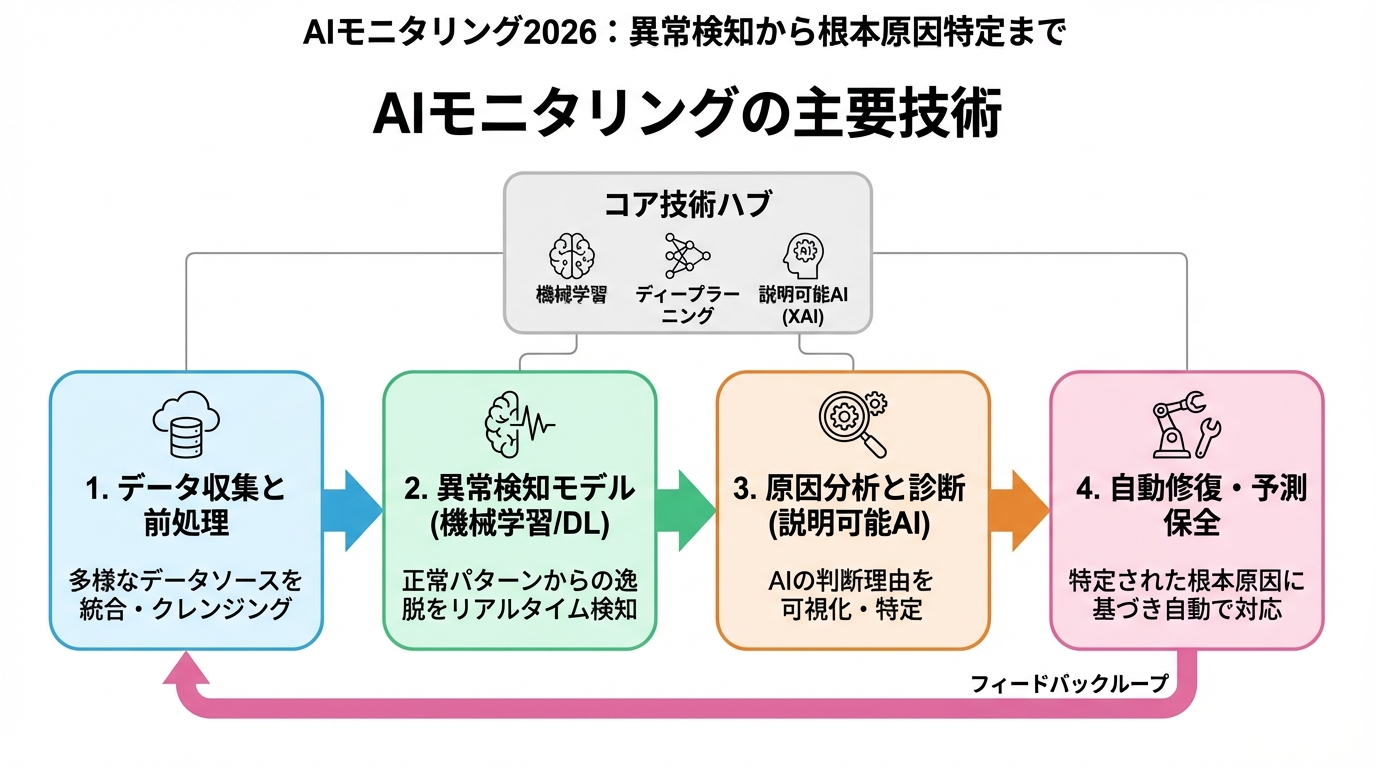
- 時系列データ分析
- 異常検知アルゴリズム
- 因果推論
- 自然言語処理
時系列データ分析
CPU使用率、メモリ使用量、ネットワークトラフィックなど、時間とともに変化するデータを分析する技術です。ARIMAモデル、LSTMネットワークなどの手法を用いて、将来の値を予測したり、異常な変動を検知したりします。
以下は、Pythonの`statsmodels`ライブラリを用いたARIMAモデルによる時系列データ分析の例です。
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
data = pd.read_csv('time_series_data.csv', index_col='timestamp')
model = ARIMA(data['value'], order=(5,1,0))
model_fit = model.fit()
forecast = model_fit.predict(start=len(data), end=len(data)+10)
print(forecast)
異常検知アルゴリズム
One-Class SVM、Isolation Forest、Autoencoderなど、正常なデータから学習し、異常なデータを検出するアルゴリズムです。これらのアルゴリズムは、事前に異常なデータを学習させる必要がないため、未知の異常にも対応できます。
以下は、Pythonの`scikit-learn`ライブラリを用いたIsolation Forestによる異常検知の例です。
from sklearn.ensemble import IsolationForest
import numpy as np
X = np.random.rand(100, 2)
model = IsolationForest(n_estimators=100, contamination='auto')
model.fit(X)
X_test = np.random.rand(10, 2)
anomaly_scores = model.decision_function(X_test)
print(anomaly_scores)
因果推論
ある事象が別の事象を引き起こす因果関係を分析する技術です。Do-calculus、構造方程式モデリングなどの手法を用いて、障害の根本原因を特定します。例えば、CPU使用率の増加が原因で、レスポンスタイムが悪化している、といった因果関係を特定することができます。
自然言語処理
ログデータやアラートメッセージなどのテキストデータを分析する技術です。テキストマイニング、感情分析などの手法を用いて、問題のパターンや傾向を把握します。例えば、特定のエラーメッセージが頻繁に発生している、といった情報を抽出することができます。
AIモニタリングの導入ステップ
AIモニタリングを導入する際には、以下のステップを踏むことが重要です。
- データの収集と整理:CPU使用率、メモリ使用量、ネットワークトラフィック、ログデータなど、必要なデータを収集し、整理します。
- AIモデルの構築と学習:収集したデータを用いて、時系列データ分析、異常検知アルゴリズムなどのAIモデルを構築し、学習させます。
- システムの統合:構築したAIモデルを、既存のモニタリングシステムに統合します。
- 評価と改善:AIモニタリングの効果を評価し、必要に応じてモデルの改善を行います。
AIモニタリングの事例紹介
実際にAIモニタリングを導入し、効果を上げている企業の事例をご紹介します。
事例1:ECサイトの障害予測
ある大手ECサイトでは、AIモニタリングを導入することで、過去のデータからトラフィックの変動パターンを学習し、サーバー負荷の急増を予測することに成功しました。これにより、事前にサーバーの増強を行い、障害の発生を未然に防ぐことができました。結果として、売上機会の損失を年間1億円以上削減することができました。
事例2:金融システムの不正検知
ある大手金融機関では、AIモニタリングを導入することで、異常なトランザクションパターンを検知し、不正アクセスを早期に発見することに成功しました。これにより、顧客の資産を保護し、企業の信頼性を維持することができました。
AIモニタリングツールの紹介
AIモニタリングを導入する際には、専用のツールを活用することも有効です。以下に代表的なツールをご紹介します。
- Datadog AI Monitoring: フルスタックの可視化とAIを活用したインサイトを提供します。
- New Relic AI Monitoring: ログ、メトリクス、トレースデータを統合的に分析し、問題の根本原因を特定します。
- Dynatrace AI Monitoring: 自動化された異常検知と根本原因分析により、迅速な問題解決を支援します。
まとめ:AIモニタリングで障害対応を効率化しよう
AIモニタリングは、従来のモニタリングシステムの課題を解決し、障害対応を効率化するための強力なツールです。この記事で紹介した技術や事例を参考に、ぜひAIモニタリングの導入を検討してみてください。障害対応から解放され、より創造的な業務に集中できる未来が待っています。


