
2026年05月
AI開発に携わる皆さん、こんにちは!AI狂の渡辺です。
最近、こんな経験はありませんか?
- デプロイしたAIモデルが、なぜか時間が経つにつれて精度が落ちていく。
- 「前はもっと賢かったのに…」と首を傾げる原因不明の性能劣化。
- 新しいデータを入れたら、かえってモデルが不安定になった。
- 学習環境が不安定で、大規模なデータ転送にいつも時間がかかり、ストレスを感じる。
ええ、よく分かります。私も、かつてはそうでした。元インフラエンジニアとしてハードウェアやネットワークの問題には慣れていましたが、AIモデルの「目に見えない病」には本当に頭を抱えました。
ChatGPTとの出会いをきっかけにAIの世界に飛び込み、フルスタックエンジニアとしてAI開発の最前線に身を置く中で、私はAIモデルの性能劣化の根本原因の多くが「データ品質」と「開発環境」に潜んでいることを痛感しました。
実際、IBMの調査(2023年)では、企業がAIプロジェクトに失敗する主な理由の一つとして、「データ品質の低さ」が40%以上を占めると報告されています1。また、スタンフォード大学の研究でも、AIシステムの運用コストの実に80%がデータ管理とデータ前処理に費やされているというデータもあります2。
本記事では、AIモデルの性能を蝕む「サイレントキラー」の正体を暴き、それを根本から解決するための「データ品質管理戦略」と「セキュアかつ高速な開発環境構築術」を、実践的なコード例や具体的な商品紹介を交えながら徹底解説します。そして、この複雑な課題に立ち向かう皆さんの脳と体を守るための秘策もお伝えしましょう。
※この記事にはPRが含まれます
AI開発者の「謎の性能劣化」はなぜ起こるのか?データ品質と環境の闇
AIモデルの開発は、一度デプロイしたら終わりではありません。むしろ、そこからが本当の戦いの始まりです。しかし、多くの開発者が直面するのが、「デプロイ後にじわじわと精度が落ちていく」という現象です。
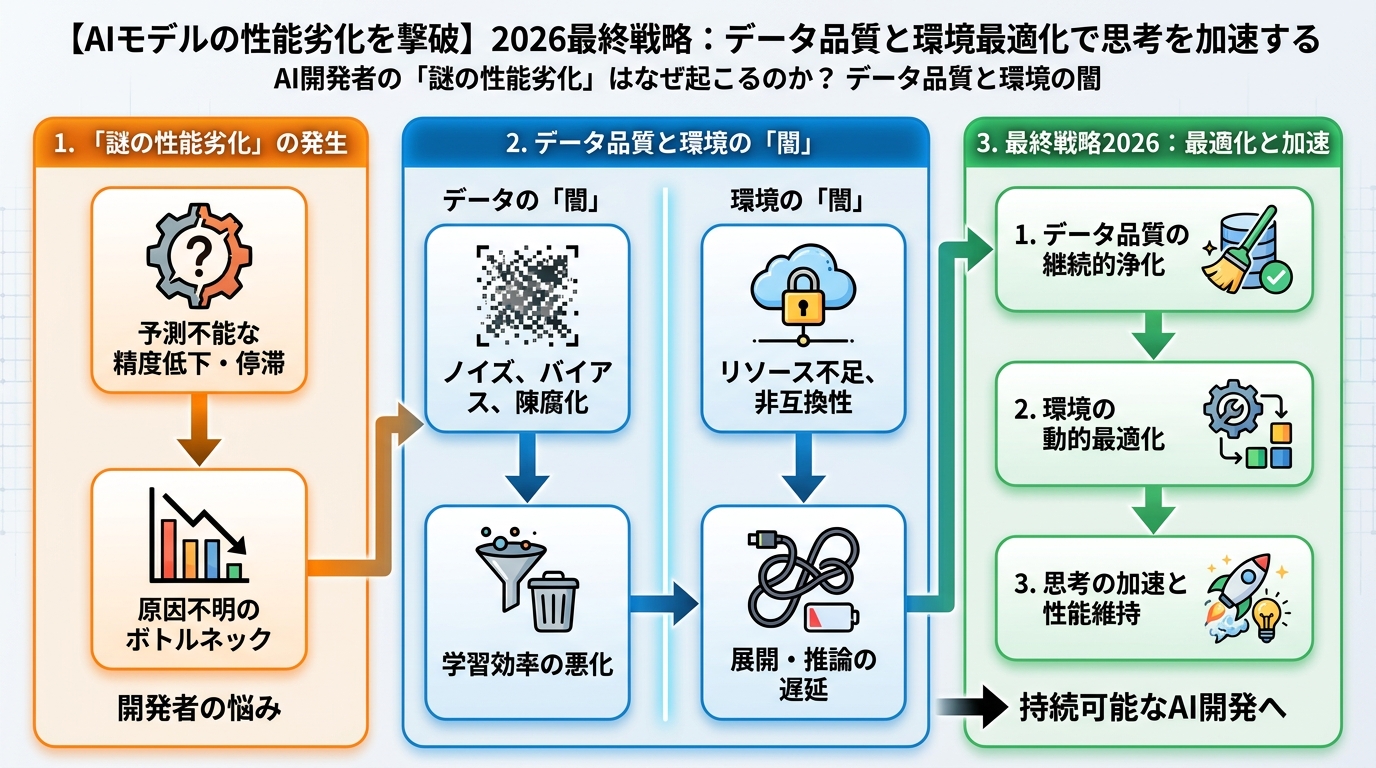
モデルが学習しない・精度が落ちる「サイレントキラー」の正体
この「サイレントキラー」の多くは、実はモデルそのものの欠陥ではなく、その「データ」と「それを扱う環境」に原因があります。
- データドリフト(概念ドリフト):時間とともに現実世界のデータ分布が変化し、モデルが学習した古いデータ分布との乖離が生じること。例: 市場トレンドの変化、ユーザー行動の変化。
- データ品質の劣化:データ収集プロセスの変更、センサーの故障、手動入力ミスなどにより、学習データや推論データの品質が知らないうちに低下すること。
- 特徴量エンジニアリングの不備:特定のデータパターンに過学習しやすく、新しいデータでは性能が発揮できない。
- インフラのボトルネック:データ転送速度の遅延、コンピュートリソースの不足、ネットワークの不安定さなどが、学習効率や推論速度を低下させる。
特に見過ごされがちなのが、後者です。学習プロセスや推論パイプラインの途中で、わずかなデータの欠損や不整合が積み重なり、最終的にモデルの出力に大きな影響を与えることがあります。これは、まるで建物の基礎が少しずつ腐食していくようなものです。
研究データが語るデータ品質の重要性
「どんなに優れたアルゴリズムを用いても、その基盤となるデータが貧弱であれば、結果として得られるAIモデルも貧弱になる。」
— Andrew Ng, Landing AI CEO (元Google Brain創設者)
これはAIの巨匠であるアンドリュー・ン氏の言葉ですが、まさにその通りです。近年では、多くの研究がデータ品質がAIモデルの性能に与える絶大な影響を指摘しています。
- マサチューセッツ工科大学(MIT)の研究では、データセット内のノイズをわずか1%削減するだけで、モデルの精度が10%以上向上するケースが報告されています3。
- Googleの研究者たちは、AIシステムを本番環境で運用する際に、モデルのデバッグよりもデータパイプラインのデバッグに圧倒的に多くの時間が費やされていると述べています4。
これらの事実は、AI開発においてデータ品質管理と、それを支える環境の最適化がアルゴリズム選定と同等、あるいはそれ以上に重要であることを示しています。
私が経験したAIモデルの「緩やかな死」:元インフラエンジニアの地獄
私のキャリアはインフラエンジニアとしてスタートしました。サーバーの構築、ネットワークの設計、システムの安定稼働。物理的なトラブルや目に見えるボトルネックには対処する術を知っていました。しかし、AIの世界は全く異質でした。
インフラからAIへ:私のターニングポイントと絶望
2020年代初頭、私はまだインフラの現場で汗を流していました。AIの波が押し寄せ、同僚たちが興奮気味にモデル開発に取り組む中、私は「サーバーが落ちなきゃいい」くらいの感覚でした。しかし、あるプロジェクトで、私が構築した環境の上で動くAIモデルが、「なぜか学習が進まない」「推論結果が不安定」という原因不明の症状に陥ったのです。
インフラのログを見ても異常なし。リソースも潤沢。モデル開発者からは「インフラのせいだ」と言われ、私からは「コードかデータがおかしい」と反論する。そんな不毛な議論が続きました。目に見えないAIモデルの内部で何が起こっているのか、私には全く理解できませんでした。それが、私のAIへの関心の始まりであり、同時に「これはインフラとは全く違う世界だ」という絶望でもありました。
ChatGPTとの出会いが教えてくれたAIの「深淵」
そんな私に転機が訪れたのは、2022年末のChatGPTの登場でした。その自然な対話能力、複雑なタスクをこなす汎用性。私は衝撃を受けました。「これだ、これが未来だ!」と。ChatGPTに質問を投げかける中で、私はAIモデルの裏側にある「膨大なデータ」と「洗練された学習プロセス」の重要性を痛感しました。
そして、ChatGPTを使い倒す中で、私はプログラミング、特にPythonを使ったデータ処理とAI開発のスキルを猛烈な勢いで習得しました。元インフラエンジニアとしての経験から、「データが流れるパイプライン」と「AIモデルというアプリケーション」を統合的に捉えることができるようになり、次第にフルスタックエンジニアとしてAI開発に深く関わるようになりました。
そこで再び直面したのが、あの「謎の性能劣化」でした。しかし、今回はインフラだけでなく、データとモデルの深部まで探る術を身につけていました。そして、ついにその原因の多くが「データ品質」にあることを突き止めたのです。あの時の絶望は、今や私の強みとなっています。
AIモデルの性能劣化は、決してエンジニアのスキル不足だけではありません。多くの場合、データと環境という、見えにくい「基礎」に問題があるのです。
AIモデルの性能を最大化するデータ品質管理戦略
AIモデルの性能を最大限に引き出し、長期的に安定稼働させるためには、厳格なデータ品質管理が不可欠です。これは、学習データだけでなく、推論時に流入するデータにも言えることです。
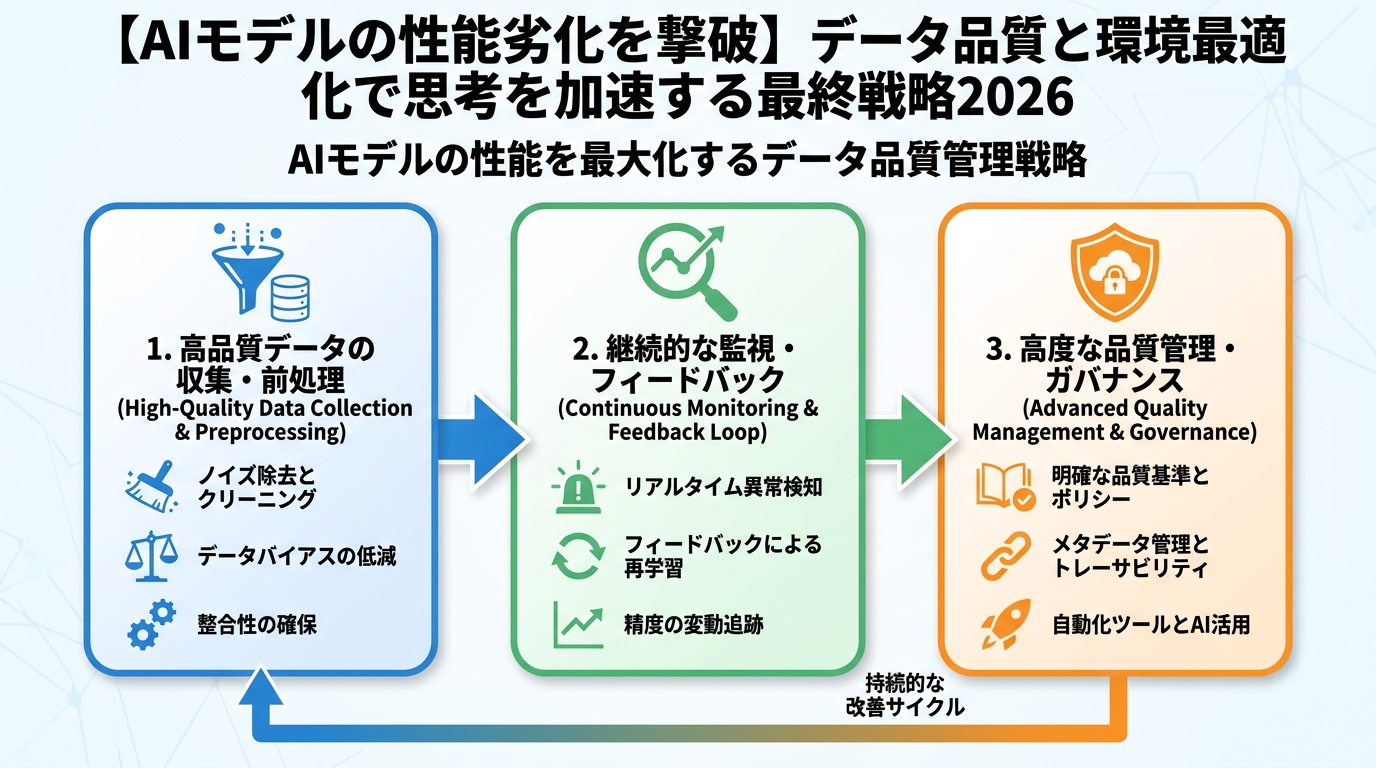
データ収集から前処理までの『品質保証』
データ品質管理は、データのライフサイクル全体を通して行うべきです。特に重要なフェーズは以下の通りです。
-
データソースの選定と検証:信頼できるソースからのみデータを取得する。APIの仕様変更、センサーの老朽化など、データソース自体の品質低下を継続的に監視する。
-
データ収集プロセスの自動化とログ管理:手動プロセスはエラーの温床。可能な限り自動化し、データの取得日時、ソース、変換ステップなどを詳細にログに残す。
-
データクレンジングと前処理の標準化:欠損値の処理、外れ値の検出と修正、データ型の統一、重複データの排除など、前処理のルールを厳密に定義し、ドキュメント化する。
-
データバリデーションの実施:データの整合性、期待される範囲内の値であるか、スキーマに準拠しているかなどを自動的にチェックする機構を導入する。
-
データバージョン管理:学習に用いたデータセットのバージョンを管理し、再現性を確保する。
実践!データ品質チェックリストと自動化のヒント(コード例)
ここでは、Pythonを使った簡単なデータ品質チェックの例を示します。実際のプロジェクトでは、Great ExpectationsやDeequといった専用のライブラリを活用することで、より堅牢なデータバリデーションパイプラインを構築できます。
データセット全体で欠損値の有無とその割合を確認します。
import pandas as pd
def check_missing_values(df: pd.DataFrame):
missing_counts = df.isnull().sum()
missing_percentages = (df.isnull().sum() / len(df)) * 100
missing_info = pd.DataFrame({
'Missing Count': missing_counts,
'Missing Percentage': missing_percentages
})
print('--- Missing Values Check ---')
print(missing_info[missing_info['Missing Count'] > 0])
if (missing_percentages > 5).any():
print('警告: 5%以上の欠損値を持つカラムが存在します。対処が必要です。')
return missing_info
期待されるデータ型と実際のデータ型が一致しているかを確認します。
def check_data_types(df: pd.DataFrame, expected_types: dict):
print('\n--- Data Type Check ---')
for col, expected_type in expected_types.items():
if col in df.columns:
actual_type = df[col].dtype
if actual_type != expected_type:
print(f"警告: カラム '{col}' の型が不一致。期待: {expected_type}, 実際: {actual_type}")
else:
print(f"カラム '{col}': 型OK ({actual_type})")
else:
print(f"警告: 期待されるカラム '{col}' がデータフレームに存在しません。")
数値データにおける外れ値をIQR(四分位範囲)に基づいて検出します。
def detect_outliers_iqr(df: pd.DataFrame, column: str):
print(f"\n--- Outlier Detection for '{column}' ---")
if not pd.api.types.is_numeric_dtype(df[column]):
print(f"カラム '{column}' は数値型ではありません。スキップします。")
return
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df[column] < lower_bound) | (df[column] > upper_bound)]
if not outliers.empty:
print(f"警告: カラム '{column}' に {len(outliers)} 個の外れ値が見つかりました。")
print(outliers[[column]].head())
else:
print(f"カラム '{column}' に外れ値は見つかりませんでした。")
# 仮のデータフレームを作成
data = {
'feature_a': [1, 2, 3, None, 5, 100, 7, 8, 9, 10],
'feature_b': ['X', 'Y', 'X', 'Z', 'Y', 'X', 'Y', 'Z', 'X', 'A'],
'target': [0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
}
df = pd.DataFrame(data)
check_missing_values(df)
check_data_types(df, {'feature_a': 'float64', 'feature_b': 'object', 'target': 'int64'})
detect_outliers_iqr(df, 'feature_a')
これらのチェックをデータパイプラインに組み込み、定期的に実行することで、データ品質の低下を早期に検知し、モデル性能の劣化を防ぐことができます。
セキュアで高速な開発環境がAIモデルを救う:VPN活用術
高品質なデータを扱う上で、そのデータが安全かつ効率的に転送・処理される環境は不可欠です。特にクラウド環境を利用したAI開発では、ネットワークの安定性とセキュリティが生命線となります。
なぜVPNがAI開発に不可欠なのか?
AI開発においてVPN(Virtual Private Network)が果たす役割は多岐にわたります。
-
機密データの保護:学習データやモデルパラメータは企業の重要な知的財産です。VPNを利用することで、公共のWi-Fiなど安全ではないネットワークからでも、暗号化されたトンネルを通じてセキュアにデータにアクセスし、情報漏洩のリスクを最小限に抑えられます。特に、外部のデータソースと連携する際には必須です。
-
安定したネットワーク接続:大規模なデータセット(テラバイト級)をクラウドストレージや分散システムとやり取りする際、ネットワークの不安定さは学習時間の延長やデータ破損に直結します。VPNは経路最適化により、安定した高速接続を提供し、転送失敗のリスクを低減します。
-
地理的制限の回避:特定の地域からしかアクセスできないデータセットやAPIを利用する場合、VPNを使えば仮想的にその地域からのアクセスを可能にし、開発の幅を広げられます。
-
M&Aにおけるセキュアな連携:複数の企業やチームが協力してAI開発を行う際、VPNは異なるネットワーク間のセキュアな接続を確立し、円滑なデータ共有と共同作業をサポートします。
私がインフラエンジニアだった頃、ネットワークの不安定さに悩まされ、学習が中断したり、データが破損したりする悪夢のような経験を何度もしました。VPNは、そうした不安定要素から私たちを守ってくれる「デジタルな防壁」なのです。
主要VPNサービス比較:NordVPN, Surfshark, ExpressVPN
AI開発者が選択すべきVPNは、速度、セキュリティ、安定性が高次元でバランスしているものです。ここでは、私が実際に利用し、推薦する3つの主要VPNサービスを比較します。
| 特徴 | NordVPN | Surfshark | ExpressVPN |
|---|---|---|---|
| サーバー数 | 約6000台 (60+カ国) | 約3200台 (100+カ国) | 約3000台 (105+カ国) |
| 同時接続数 | 最大6台 | 無制限 | 最大8台 |
| 速度 | 非常に高速 (独自プロトコルNordLynx) | 高速 (WireGuardプロトコル) | 非常に高速 (独自プロトコルLightway) |
| セキュリティ | AES-256暗号化、Kill Switch、脅威対策 | AES-256暗号化、CleanWeb、NoBordersモード | AES-256暗号化、TrustedServer技術 |
| ログポリシー | ノーログポリシー(独立監査済み) | ノーログポリシー(独立監査済み) | ノーログポリシー(独立監査済み) |
| 価格帯 | 中~高 (長期契約で割引) | 低~中 (長期契約で割引) | 高 (長期契約で割引) |
| おすすめポイント | 総合的なバランスが良く、安定性抜群。大規模データ転送に強み。 | 低価格で無制限接続が魅力。複数のデバイスやチームでの利用に。 | 圧倒的な速度と安定性。ミッションクリティカルな開発に最適。 |
👉 横にスクロールできます
私の場合、大規模なデータセットを扱うことが多いため、NordVPNの安定した高速接続と強力なセキュリティ機能は欠かせません。チームで複数のプロジェクトを同時に進める際には、Surfsharkの無制限接続が非常に役立ちます。とにかく速度と信頼性を追求するならExpressVPNが最適でしょう。これらのVPNサービスを導入することで、開発環境の信頼性が劇的に向上し、安心してAI開発に集中できるようになります。
データ品質の番人が最高のパフォーマンスを発揮するために:睡眠の質を高める
ここまでデータ品質管理と開発環境の最適化について語ってきましたが、これらを実践するのは人間です。AIモデルの番人である私たち自身のパフォーマンスが低下しては元も子もありません。
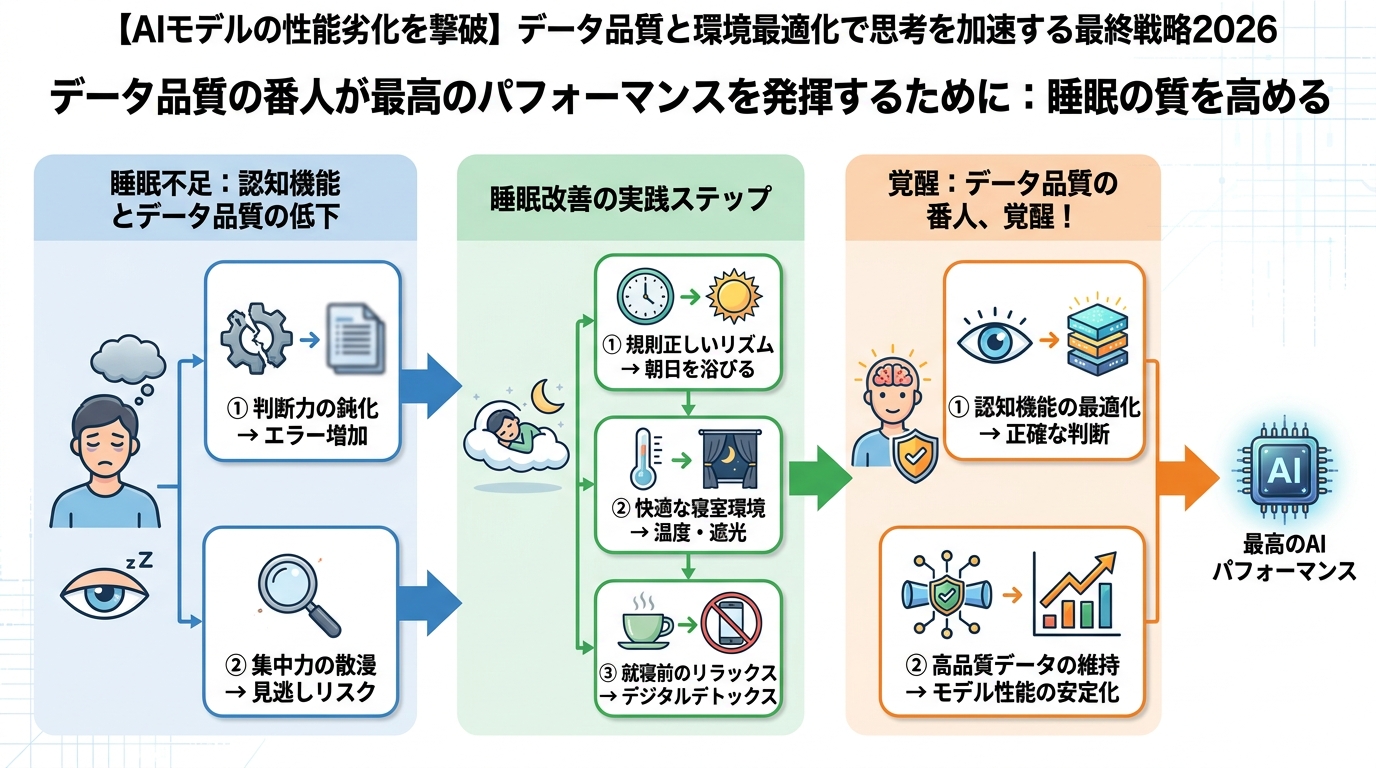
データ品質管理のストレスと戦う脳への投資
データ品質の問題は、非常に厄介で、時に泥臭い作業を伴います。原因不明のバグ、データソースの仕様変更、急な欠損値の増加…。これらは開発者の脳に多大なストレスを与え、集中力、問題解決能力、そして創造性を著しく低下させます。
睡眠不足がパフォーマンスに与える影響は深刻です。ハーバード大学医学部の研究では、6時間の睡眠を2週間続けると、48時間徹夜したのと同じくらい認知機能が低下すると報告されています5。データ品質管理のような、細部にわたる注意と論理的思考が求められるタスクにおいて、これは致命的です。
質の高い睡眠は、脳の疲労回復、記憶の定着、ストレスホルモンの抑制に不可欠です。私自身、インフラエンジニア時代は徹夜が当たり前で、常に頭がぼーっとしていました。しかし、AI開発の複雑さに直面し、「最高のパフォーマンスは質の高い休息から生まれる」と痛感するようになりました。
最高のパフォーマンスを生む快眠寝具:NELLとGOKUMIN
質の良い睡眠は、質の良い寝具から。AI開発者の皆さんの脳と身体への最高の投資として、私が実際に愛用し、推薦する快眠寝具をご紹介します。
-
NELLマットレス:
「寝返りの打ちやすさ」を徹底的に追求したポケットコイルマットレスです。AI開発者は長時間座っていることが多く、肩や腰に負担がかかりがち。NELLは体圧分散性に優れ、寝返りをサポートすることで、血行促進と体の歪み防止に貢献します。朝起きた時の体の軽さは感動ものです。質の高い睡眠が、日中の集中力と問題解決能力を飛躍的に向上させてくれます。 -
GOKUMINマットレス/枕:
手頃な価格帯で高品質な睡眠を提供するGOKUMINは、コストパフォーマンスを重視するAI開発者におすすめです。特に高反発マットレスは、体の沈み込みすぎを防ぎ、正しい寝姿勢を保ちます。私が使っているのはGOKUMINの低反発枕ですが、首へのフィット感が素晴らしく、首や肩のコリが劇的に改善されました。寝具に投資することは、日中のクリエイティブな思考時間を最大化するための最良の方法です。
データ品質管理という繊細な作業を最高の状態でこなすには、最高の頭脳が必要です。その頭脳を支えるのは、何よりも質の高い睡眠なのです。
未来を創るAI開発者へ:データと環境、そして自己投資
AIモデルの「謎の性能劣化」は、もはや避けられない課題ではありません。データ品質の管理、セキュアで高速な開発環境の構築、そして私たち自身の身体への投資。これら3つの柱を確立することで、AIモデルのポテンシャルを最大限に引き出し、持続可能な開発を実現することができます。
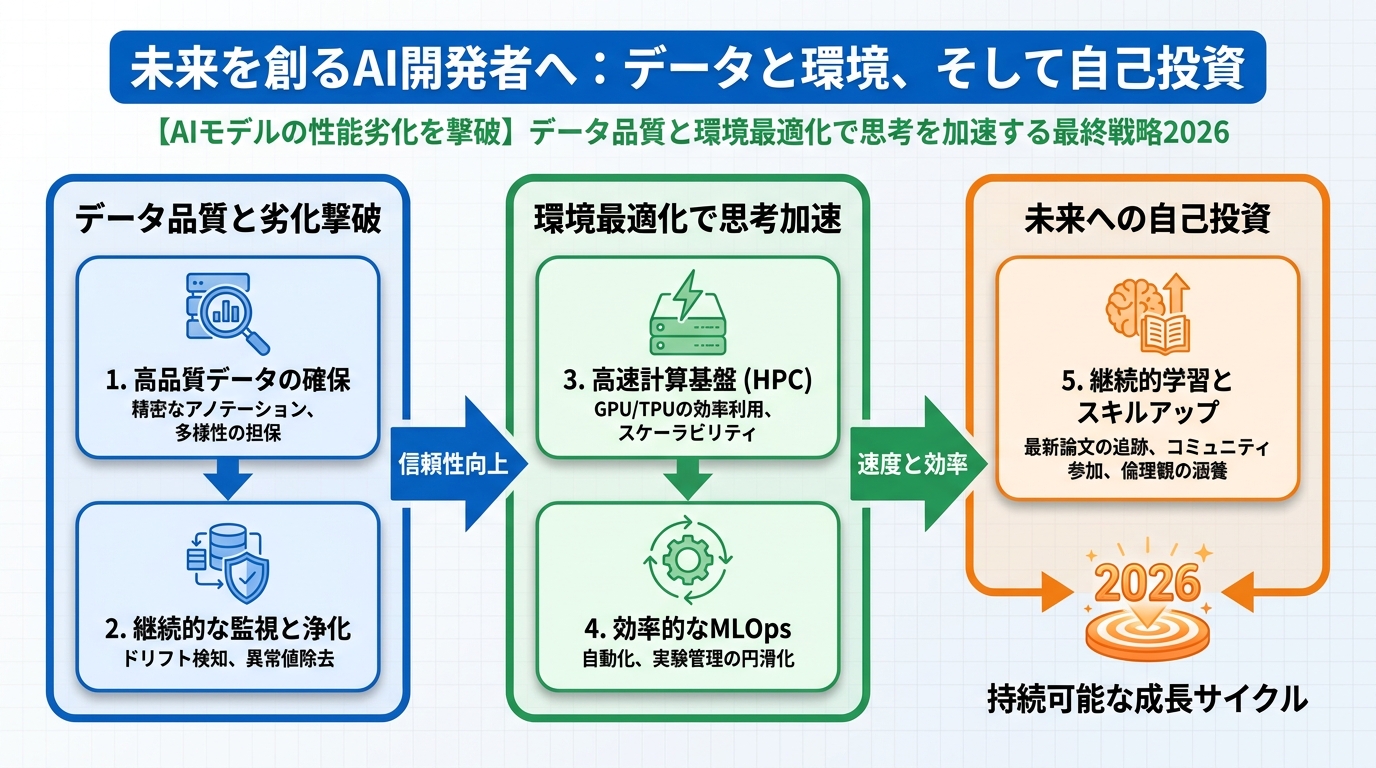
- ✅ データ品質の番人となれ:データソースから前処理まで、徹底した品質保証プロセスを導入し、データドリフトやデータ品質劣化を早期に検知・対処する。
- ✅ VPNで開発環境を武装せよ:NordVPN、Surfshark、ExpressVPNのような信頼性の高いVPNサービスを導入し、機密データの保護と安定した高速データ転送を確保する。
- ✅ 自己投資で脳を覚醒させよ:NELLやGOKUMINなどの質の高い寝具に投資し、データ品質管理のストレスから解放された、深く質の高い睡眠で最高のパフォーマンスを引き出す。
かつて、インフラの深淵でAIモデルの謎の病に苦しんだ私だからこそ、皆さんの痛みがよく分かります。しかし、今ではこれらの戦略を実践することで、私は自信を持ってAIモデルをデプロイし、その性能を長期的に維持できるようになりました。
高品質なデータと最適化された開発環境があれば、あなたは「バグの修正」ではなく、「新たな価値の創造」に集中できます。そして、質の良い睡眠は、その創造性を無限に広げる燃料となるでしょう。
AI狂の渡辺として、私はこれからも皆さんと共に、AIの未来を切り拓いていくことを誓います。
参考資料:
- IBM Research Blog: The impact of data quality on AI projects
- Stanford University: Hidden Technical Debt in Machine Learning Systems
- MIT News: The importance of data quality in AI
- Google Developers: Machine Learning Rules of Thumb
- Harvard Health Publishing: The importance of sleep in improving cognitive performance


